From Ranking Pages to Selecting Sources
In traditional SEO, strategy has primarily revolved around a familiar question:
“How do we rank higher for this keyword?”
The primary unit of competition was the web page in a list of search results. You optimised titles, improved content, gained backlinks, and monitored movement up and down the SERP.
LLM-based search engines fundamentally change this frame.
Systems such as:
- ChatGPT with browsing,
- Perplexity,
- AI-powered overviews in search engines, and
- Other LLM-integrated assistants
Do not simply return ranked lists. Instead, they:
- Interpret the user’s query or prompt in natural language.
- Retrieve potentially relevant content from the web or their index.
- Generate a synthesized, conversational answer, often referencing multiple sources.
- Optionally display a small set of citations or links.
The competitive question, therefore, becomes:
“When an LLM-based search engine assembles an answer,
What data and signals does it use to choose our content as one of its sources?”
While no vendor discloses its complete internal ranking logic, we can reasonably infer the major signal categories from:
- Observed behaviour,
- Information retrieval and machine learning practices, and
- Public documentation and research trends.
This article organizes those signals into practical, actionable groups and explains how you can align your content and site with them in 2026.
What Is an LLM-Based Search Engine?
An LLM-based search engine is any search or answer system that uses a large language model as a core component of the user experience. Rather than returning only a static list of documents, the system:
- Interprets complex, conversational queries.
- Retrieves relevant documents or passages.
- Uses an LLM to summarise, explain, compare, or recommend.
- Often presents a unified answer with citations to underlying sources.
Examples include:
- ChatGPT with browsing – responding to open-ended questions with cited web sources.
- Perplexity – blending web search and LLM summarisation, with inline citations.
- AI answer boxes / AI overviews – in search engines that generate a high-level answer at the top of the SERP.
A simplified pipeline looks like this:
- Query Understanding
- Parse the query, detect entities and intent, and understand constraints (e.g., “2026”, “for B2B SaaS”, “step-by-step”).
- Parse the query, detect entities and intent, and understand constraints (e.g., “2026”, “for B2B SaaS”, “step-by-step”).
- Retrieval
- Identify and fetch relevant content from an internal index and/or the open web.
- Identify and fetch relevant content from an internal index and/or the open web.
- Re-ranking / Source Selection
- Score candidate passages and pages based on relevance, quality, and trustworthiness.
- Score candidate passages and pages based on relevance, quality, and trustworthiness.
- Answer Generation
- Use the LLM to construct a coherent response using selected passages as input.
- Use the LLM to construct a coherent response using selected passages as input.
- Attribution
- Determine which sources to highlight as citations in the UI.
The rest of this article focuses on the signals that influence steps 2–4: retrieval, re-ranking, and generation.
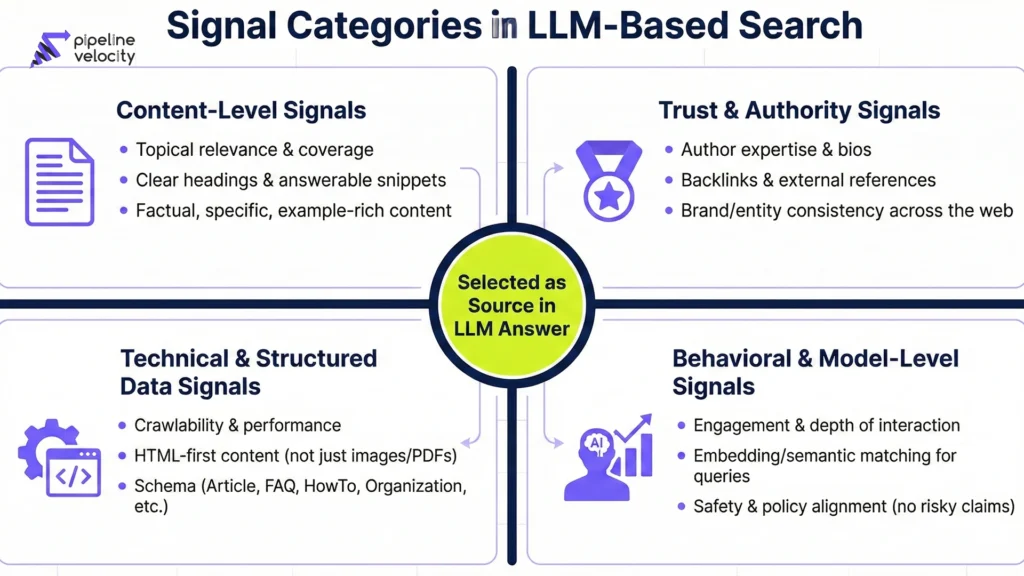
Core Signal Categories in LLM-Based Search
For practical purposes, it is helpful to group signals into six categories:
- Content-level signals – what is actually written on your pages.
- Page- and site-level trust signals – how credible you appear as a source.
- Technical and structured data signals – how accessible and machine-readable your content is.
- Behavioral and engagement signals – how real users interact with your content.
- Model- and retrieval-level signals – how your content is represented and evaluated within LLM and retrieval systems.
- Context and alignment signals – how well your content matches the user’s specific intent, constraints, and safety requirements.
We will look at each group in more detail and discuss what you can actually do about it.
Content-Level Signals: What Is on the Page
Content remains the primary input to any search or answer system. For LLM-based search, three questions dominate:
- Is this content relevant to the user’s query?
- Is it structured in a way that makes it easy to reuse?
- Is it safe and helpful to include as part of a generated answer?
Topical Relevance and Coverage
LLM-based engines still rely on core information retrieval concepts:
- Lexical relevance – the presence of essential terms and phrases.
- Semantic relevance – the conceptual alignment between query and content, beyond exact keywords.
- Topical coverage – how comprehensively you cover related aspects of a topic.
For you, this translates into:
- Building topic clusters, rather than isolated, one-off articles.
- Ensuring pillar pages address:
- Definitions and fundamentals,
- Implementation and how-to guidance,
- Comparisons and evaluation criteria, and
- Common pitfalls and FAQs.
- Definitions and fundamentals,
- Using language that reflects how your audience actually describes their problems in natural language, rather than only internal jargon.
Well-covered topics give LLM-based engines multiple passages and angles to draw from when constructing an answer.
Clarity, Structure, and “Answerability”
LLMs work with text in segments (paragraphs, sections, passages). They look for text that can serve as a good answer to a specific question or sub-question.
Signals that help here include:
- Clear, descriptive headings – especially question-based headings such as:
- “What is [concept]?”
- “How does [concept] work?”
- “What are the benefits and limitations of [approach]?”
- “What is [concept]?”
- Concise lead paragraphs – each key section should open with 2–4 sentences that directly answer the implied question.
- Lists, steps, and frameworks – structured formats that are easy for an LLM to recognise and reuse as bullet points or step-by-step instructions.
Practically, content is more “answerable” when it follows a pattern:
Heading (question or clear topic)
→ short, direct answer
→ additional explanation, examples, and nuance.
Factuality, Specificity, and Use of Examples
LLM providers place increasing emphasis on reducing hallucinations and incorrect answers. As a result, content that is:
- Specific – using concrete numbers, timeframes, and conditions where appropriate.
- Grounded – referencing standards, definitions, or accepted practices where relevant.
- Illustrated – using examples and scenarios that make the abstract concrete.
…is inherently more attractive as a source.
To support this:
- Replace generic claims (“up to 10x better”) with clearer, honest ranges or directional statements.
- Add short, realistic scenarios (e.g., “For a mid-market SaaS company selling to North America, this might look like…”).
- Explicitly indicate limitations or assumptions when offering recommendations.
Tone, Intent, and Helpfulness
Content that is overtly manipulative, purely promotional, or misleading is risky for LLM systems to use. In contrast, content that is:
- Neutral to moderately opinionated,
- Balanced in its presentation of trade-offs, and
- Clearly focused on helping the reader make a better decision.
It is more likely to be treated as a safe building block in generated answers.
A professional, informative, and user-centric tone is not only good brand practice but also an LLM trust signal.
Page- and Site-Level Trust Signals
Beyond the words on a single page, LLM-based search engines consider the broader context: who is publishing this content, and how credible are they?
Authority and Expertise
Indicators of real expertise include:
- Author-level signals
- Named authors with clear bios.
- Descriptions of expertise, roles, and relevant experience.
- Consistent association of authors with specific domains (e.g., AI search, technical SEO, B2B marketing).
- Named authors with clear bios.
- Site-level clarity
- Clear “About” and “Services” pages explaining what the organisation does.
- Evidence of operating in the domain (case studies, clients, partnerships, or products).
- Clear “About” and “Services” pages explaining what the organisation does.
- Topical focus
- Publishing regularly on a coherent set of topics, rather than producing miscellaneous content with no pattern.
- Publishing regularly on a coherent set of topics, rather than producing miscellaneous content with no pattern.
These elements help an LLM-based system distinguish between a generalist blog and a site that can reasonably be treated as an expert source on a specific topic.
Backlinks and External References
Link-based signals are unlikely to disappear entirely in the age of AI search. They remain a proxy for:
- Industry recognition,
- Peer validation, and
- Real-world value.
Key points:
- A smaller number of high-quality, contextually relevant backlinks is generally more meaningful than a large number of weak or artificial links.
- Being cited in reputable publications, research, or authoritative blogs signals that your content is worth reading and reusing.
For LLM-based search, external references are not merely about PageRank; they support the judgment:
“If other credible entities rely on this source, it is safer for us to rely on it as well.”
Brand and Entity Consistency
Search systems increasingly represent organisations and people as entities in a knowledge graph. Consistency across appearances strengthens this representation.
Signals include:
- Consistent use of brand name, logo, and description across your website, social profiles, and major directories.
- Structured markup for Organization, LocalBusiness, Product, and Service where appropriate.
- Coherent messaging about what you do and who you serve.
The more clearly and consistently you present yourself, the easier it is for LLM-based systems to connect different pieces of content back to a single, trustworthy entity.

Technical and Structured Data Signals
No matter how good your content is, it must be technically accessible and machine-readable for LLM-based search engines to use effectively.
Crawlability, Performance, and Accessibility
Foundational technical SEO principles remain relevant:
- Crawlability
- Logical internal linking and clean URL structures.
- XML sitemaps that include key content.
- Avoid unnecessary blocking in robots.txt or meta tags.
- Logical internal linking and clean URL structures.
- Performance and stability
- Reasonable page load times, especially on mobile.
- Limited layout shifts and intrusive interstitials.
- Reliable rendering of main content without requiring complex client-side execution.
- Reasonable page load times, especially on mobile.
- Accessibility of core content
- Key text in standard HTML elements (headings, paragraphs, lists), not only in images or embedded files.
- Minimal reliance on unconventional DOM structures that hinder parsing.
- Key text in standard HTML elements (headings, paragraphs, lists), not only in images or embedded files.
If your most essential explanations live only in PDFs, screenshots, or complex client-side apps, they are significantly harder for AI systems to index and reuse.
Structured Data and Schema Markup
Structured data provides explicit, machine-readable context. Commonly relevant types include:
- Content-focused schema
- Article / BlogPosting – for long-form guides and posts.
- FAQPage – for pages with multiple Q&A pairs.
- HowTo – for procedural, step-by-step content.
- Article / BlogPosting – for long-form guides and posts.
- Entity-focused schema
- Organization / LocalBusiness – for company details.
- Product / Service – for offerings and features.
- Organization / LocalBusiness – for company details.
- Supporting properties
- Author, datePublished, dateModified, headline, description, etc.
- Author, datePublished, dateModified, headline, description, etc.
Exemplary schema implementation assists:
- Traditional search results (rich snippets, FAQ rich results are still supported.
- AI answer systems that rely on structured data to understand page type, Q&A pairs, and entity relationships.
Freshness and Update Signals
For topics that evolve rapidly, “freshness” can be a meaningful signal:
- Recent updates – indicated by dateModified, updated examples, or references to current versions of tools and standards.
- Timely coverage – addressing changes in platforms, regulations, or practices that are relevant to your audience.
This does not mean constantly rewriting everything. It does mean:
- Identifying which pages must remain current (e.g., AI search strategies, platform-specific guides).
- Establishing a realistic review cadence (e.g., every 3–6 months) for those assets.
LLM-based engines must balance stable knowledge with up-to-date information. You want your content to fall into the category of “reliably current” where it matters.
Behavioral and Engagement Signals
While the exact weight and implementation vary, user behaviour can still offer strong hints about content quality and usefulness.
Indicators may include:
- Time spent on the page and scroll depth.
- Low bounce rates for high-intent queries.
- High engagement with internal links and calls-to-action.
- Return visits to cornerstone guides or resource pages.
These signals do not operate in isolation, but they contribute to a profile of content that:
- Meets user expectations,
- Answers questions effectively, and
- Encourages further interaction.
From an LLM perspective, user engagement suggests that citing you is less likely to result in poor user experiences downstream.
Model- and Retrieval-Level Signals
LLM-based search introduces additional layers that go beyond classic SEO ranking factors.
Embedding Similarity and Semantic Matching
Many LLM-based retrieval systems use vector embeddings to represent:
- Queries, and
- Content segments (paragraphs, sentences, or sections).
They then retrieve content based on semantic similarity rather than just keyword overlap.
To perform well in this context:
- Use natural, conversational language that resembles how your audience phrases questions.
- Cover adjacent subtopics and follow-up questions within the same piece, where logical.
- Avoid awkward keyword stuffing; embeddings are sensitive to meaning and context rather than exact phrase repetition.
The aim is for your content segments to “sit close” in semantic space to the kinds of prompts your audience is likely to use.
Retrieval-Augmented Generation (RAG) Considerations
In retrieval-augmented generation (RAG) setups, a retriever selects relevant content chunks, which the LLM then uses as context to generate answers.
Implications for your content:
- Chunk quality
- Paragraphs and sections should be self-contained enough that, when retrieved, they make sense with minimal additional context.
- Paragraphs and sections should be self-contained enough that, when retrieved, they make sense with minimal additional context.
- Redundancy and reinforcement
- Key definitions and explanations can appear (appropriately) in more than one place. Multiple correct, coherent segments increase the likelihood that at least one will be retrieved and used.
- Key definitions and explanations can appear (appropriately) in more than one place. Multiple correct, coherent segments increase the likelihood that at least one will be retrieved and used.
- Consistent framing
- Avoid contradicting yourself across different pages or sections. Conflicting explanations from the same source reduce trust and can confuse models.
Good editorial discipline improves how your content behaves in retrieval scenarios.
Safety, Policy, and Alignment Filters
LLM providers apply safety and policy filters to avoid:
- Harmful or illegal content,
- Misinformation in sensitive domains (e.g., health, finance, legal), and
- Outputs that conflict with their usage guidelines.
As a result:
- Content that is overtly risky, sensational, or irresponsible is less likely to be used, even if it is technically relevant.
- In regulated areas, clear disclaimers, balanced language, and references to guidelines or official sources help reduce perceived risk.
It is advisable to:
- Be explicit about what your content is not (e.g., “This is not financial advice”).
- Use cautious, precise phrasing where legal or health outcomes are involved.
- Avoid overselling or guarantees.
This is both a brand-safety measure and a practical requirement for being considered a reliable source by LLM systems.
How LLM-Based Search Differs From Traditional SEO
There is substantial overlap between traditional SEO and LLM-based search optimisation. However, several shifts are noteworthy:
- From pages to passages
- Traditional SEO primarily evaluates entire URLs.
- LLM search often evaluates and selects specific segments within those URLs.
- Traditional SEO primarily evaluates entire URLs.
- From clicks to answers
- Classic SEO success is measured in rankings and click-throughs.
- LLM search success includes being part of the answer, even when a user does not click.
- Classic SEO success is measured in rankings and click-throughs.
- From single-query optimisation to multi-intent coverage
- Traditional optimisation often targets narrow keyword groups.
- LLM answers often blend several intents (definition, use case, pros/cons, next steps), requiring broader coverage within a single piece of content.
- Traditional optimisation often targets narrow keyword groups.
- From static SERPs to dynamic conversation
- In LLM-based interfaces, users ask follow-up questions.
- The system continually retrieves and re-ranks sources as context evolves.
- In LLM-based interfaces, users ask follow-up questions.
In practice, this means:
- Continuing to invest in strong, technically sound SEO.
- Adding an “LLM lens” to key assets:
“If an LLM had to construct a robust answer using only our site, how easy are we making that?”
Practical Checklist: Making Your Site LLM-Friendly
Below is a consolidated checklist you can use to plan or review content and site health.
Content and Structure
- Each key page has a clearly defined primary topic and audience.
- There is a concise, quotable summary or definition near the top.
- Several headings are written as natural-language questions.
- Paragraphs are short (2–4 sentences) and focused on one idea.
- Essential concepts are presented with lists, steps, or frameworks where appropriate.
- Tone is professional, neutral to helpful, and user-centric.
- Content includes concrete examples, scenarios, or simple case snippets.
Trust and Authority
- Authors are named, and their bios are visible, demonstrating relevant expertise.
- “About” and “Service” pages clearly explain who you are and what you do.
- You publish consistently on defined topic clusters (e.g., LLMO, GEO, AI search, industry-specific applications).
- You maintain an ongoing effort to earn high-quality, relevant backlinks and mentions.
Technical Foundation and Schema
- The site is reasonably fast and stable on desktop and mobile.
- Main textual content is rendered in plain HTML and is easy to parse.
- You use appropriate schema types (Article, FAQPage, HowTo, Organization, Service, etc.).
- Important pages are included in sitemaps and are internally linked from logical places.
Behaviour and Engagement
- You monitor engagement metrics (time on page, scroll depth, conversions where relevant).
- Underperforming or high-exit pages are periodically reviewed and improved.
- Critical content is refreshed on a 3–6 month cadence, especially in fast-moving domains (e.g., AI search, LLM tooling).
AI-Specific Practices
- For your key themes, you have mapped realistic prompts your audience might ask AI tools.
- You periodically test those prompts in LLM-based search interfaces (e.g., ChatGPT with browsing, Perplexity) to observe current answers and citations.
- Based on those observations, you refine:
- Definitions and summaries.
- Coverage of common follow-up questions.
- The clarity and structure of your main guides.
- Definitions and summaries.
You do not need to achieve perfection across every item to see improvement. Even incremental alignment with these principles can meaningfully increase your suitability as a source for LLM-based search engines.
FAQ: LLM Trust Signals and AI Search
Q1. Do backlinks still matter for LLM-based search?
Yes. While LLM-based systems introduce new types of signals, links remain a strong indicator of authority and relevance. In an AI search context, the quality and context of those links are often more important than sheer quantity.
Q2. Can I optimise separately for ChatGPT, Perplexity, and other AI systems?
You cannot tune for each proprietary model individually. What you can do is align with shared principles: clear structure, strong topic coverage, trustworthy content, and solid technical implementation. These fundamentals translate across different AI-powered search tools.
Q3. Does AI search make traditional SEO obsolete?
No. LLM-based search systems still depend on web content and underlying search infrastructure. Strong technical SEO, well-structured content, and robust authority signals are still prerequisites. AI search builds on those foundations rather than replacing them.
Q4. How can I tell if LLMs are already using my content?
There is no complete, centralised view. However, you can:
Test realistic prompts in LLM-based tools and look for your URLs among the citations.
Track unusual referral patterns or AI-related user agents where visible.
Observe whether your language, frameworks, or terminology appear in AI-generated answers.
Treat these observations as qualitative guidance rather than precise metrics.
Q5. If I can only do one thing, where should I start?
For most organisations, the highest-impact starting point is to restructure existing high-value pages to be more answer-friendly:
Add clear, concise definitions at the top.
Introduce question-based headings.
Break down explanations into short paragraphs, lists, and steps.
Add a short FAQ section at the end of each core guide.
This approach improves usability for human readers and simultaneously makes your content more suitable for retrieval and reuse by LLM-based search engines.
By treating LLM-based ranking and trust signals as an evolution of search, rather than an entirely separate discipline, you can gradually adapt your content, site architecture, and measurement practices. The result is a body of work that is not only more discoverable in AI-driven environments but also more coherent, trustworthy, and valuable for the people you ultimately want to reach.



